Introducing IPFS and Filecoin
An overview of what they are, what they solve, and how they work together.

Welcome to another edition of Crypto Explained. We are on the mission of making crypto easy for everyone. If you’d like to learn more about the world of crypto, don’t forget to subscribe to receive this Newsletter directly in your email!
We live and work on the Internet.
However, the web as we know it today has a key problem, and this is because all the information on it is centralized, stored in big server farms owned and managed by, yes you guessed it, tech giants like Alphabet, AWS, and Microsoft.
It’s like putting all your eggs in one basket. Either because there is an outage, or access issues, or shut down.
What other alternatives do we have, you ask? Great question. Today we are going to answer this question by diving into this magic pair…
Originally, I only intended to write about Filecoin, but to really understand the scope of what Protocol Labs is building, we need to get the whole story, so allow me to introduce to you both IPFS and Filecoin in today’s edition of Crypto Explained.
First things first: Quick facts!
Protocol Labs is an R&D lab based in San Francisco, founded by Juan Benet in 2014.
The goal of Protocol Labs is to build the next generation of the Internet.
In order to achieve this, they are building an ecosystem of protocols that can enable this vision: IPFS and Filecoin are the two main developments that Protocol Labs launched:
IPFS: launched in 2015, is an open source peer-to-peer decentralized system for storing and accessing all digital files.
Filecoin: the mainnet launched in October 2020. It is a decentralized storage network that is used as the incentivization layer powered by cryptocurrency.
FIL is the native coin of Filecoin, built on the Filecoin Blockchain (more on its tokenomics later).
Now, let’s break this down!
Chapter 1 - All about IPFS
IPFS stands for InterPlanetary File System. A mouthful, I know. You are probably thinking… hold on, did she just say “planetary”? I certainly did, but don’t let this ultra ambition name confuse you.
It is just an idealistic name that essentially representes their drive to build a system that can work across places as disconnected or as far apart as planets.
What problem is it trying to solve?
IPFS is trying to surpass HTTP to build an open and more resilient web.
As we already mentioned before, today’s web is centralized:
Which represents a single point of failure.
It also makes it easier to censor
Inefficient and Expensive: HTTP downloads files from one server at a time, which is a methodology that consumes additional bandwidth.
Why is IPFS better?
Supports a resilient internet: If someone attacks Wikipedia's web servers or an engineer at Wikipedia makes a big mistake that causes their servers to catch fire, you can still get the same webpages from somewhere else.
Makes it harder to censor content: Because files on IPFS can come from many places, it's harder for to block things.
Can speed up the web: If you can retrieve a file from someone nearby instead of a server farm hundreds or thousands of miles away, you can often get it faster.
Bandwidth: files don’t need to go back and forth to central servers, and therefore saving bandwidth.

So how does IPFS achieve this?
There are three fundamental principles to understanding IPFS:
Unique identification via Content Addressing
Content linking via Directed Acyclic Graphs (DAGs)
Content discovery via Distributed Hash Tables (DHTs)
1. Location based Addressing vs Content based Addressing
Instead of being location-based, IPFS addresses a file by what's in it, or by its content. This means that, instead of saying where to find it, it just says what it is you want.
When you add a file to IPFS, your file is split into smaller chunks, cryptographically hashed, and given a content identifier (CID). This CID acts as a permanent record of your file as it exists at that point in time.
Think of these content identifiers as the files’ unique fingerprints.
2. Directed acyclic graphs (DAGs) - merkle DAGs
We already established that your file gets split into different blocks, and gets assigned a unique CID.
Now IPFS uses Merkle DAGs as the mechanism to structure all this data. So in a nutshell, it is an optimized way for representing directories and files.
Different parts of your file can be stored in different places, so eventually when you or anyone needs it, it come come from different sources at the same time, and be authenticated in a fast manner.
The fact that content is split in different chunks is also benefitial because common chunks across files can be reused in order to minimize storage costs, and therefore deduplicating data.
So to sum up, IPFS lets you give CIDs to content and link that content together in a Merkle DAG.

3. Distributed Hash Table (DHT)
A hash table is a database of keys to values. A distributed hash table is one where the table is split across all the peers in a distributed network.
This is used to find the content you need.
When someone needs to look up a file, what happens in the backend is that the system will identify which peer nodes have this file by referencing to the file's CID, and get it from the best option.
When this someone views or downloads your file, they cache a copy — and become another provider of your content until their cache is cleared.
Now, if anyone adds a new version of your file to IPFS, its cryptographic hash is different, and therefore it will get a new, different CID. This means files stored on IPFS are resistant to tampering and censorship — any changes to a file don't overwrite the original.
…………………..
All sounds great so far, right?
But we are talking about a peer to peer network here… we can’t possibly believe that anyone will be storing this content for you simply because they are nice.
So how does IPFS ensure all files are available? I’m so glad you asked.
Enters, Filecoin.
Chapter 2 - All about FILECOIN
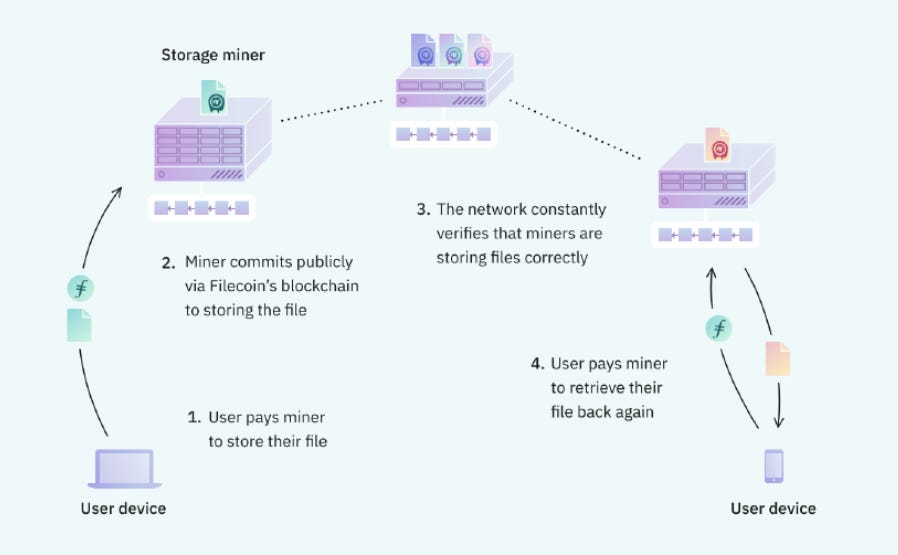
Filecoin is created as the incentive layer for IPFS: it is a blockchain built on top of IPFS, and as such it has all the components of a blockchain, including of course its own native cryptocurrency (FIL) which is the key incentive mechanism.
It’s goal is to create a decentralized cloud storage that is independent from third parties.
These files are replicated on many nodes so they cannot become unavailable.
Filecoin runs on a dual consensus mechanism:
Proof of Replication: this is the initial proof that a given piece of data has been stored by the miner, and must be submitted to the blockchain upon creation of a data storage contract with a client.
Proof of Space Time: this is the proof that miners are still storing the data over time, and must be submitted periodically to the netowrk. If this fails, then some of the staked amount is slashed.
The Filecoin blockchain iitself doesn’t store any files. It is the ledger for transactions and Filecoin addresses balances, as well as agreements between client and miners.
Tokenomics
FIL is the native currency of the Filecoin blockchain.
It has a maximum supply of 2B FIL.
In 2017 it raised over 200M on their ICO.
FIL is used as:
Rewards to miners for the storage they provide the network. These rewards are proportional to how much hard drive space is committed to the network.
Payment fee by people using the storage system
Payment fee to retrieval miners to fetch the file.
FIL is technically a deflationary asset since any slashed staked from storage miners are fully burnt.
In terms of supply distribution:
Around 30% of supply is with protocol labs and private investors.
The remaining 70% will be minted in 3 ways:
up to 770M based on performance on the network (over a 20 year period),
300M over 30 years period (simple minting), and
additional 300M (mining reserve) to incentivize future types of mining.
What is Filecoin solving for?
Currently, centralized cloud services are spread thinly around the world, which means you can be very far away from your data and makes it hard to access.
This also means that prices can be very high as you don’t have much alternatives.
And, as we already said, these tech giants own your data, and it can suffer loss, outages, as well as censorship.
So what Filecoin is trying to do is to create an open market, with a new storage and economic model by:
Filecoin reduces the barriers to entry for storage providers and incentivizes nodes to put extra storage to work.
This combination allows for more supply to meet the growing demand, while lowering the price due to increased competition.
Cryptographic proofs to guarantee that your data is always available
To summarize…
Protocol Labs is building the next generation of the Internet with 2 compatible solutions:
IPFS powers Web3 and the distributed web
Filecoin enables the decentralized storage
Now, it is important to understand that Filecoin is fully compatible with IPFS, but IPFS is storage layer agnostic, which means ultimately you can use the storage of your choice, doesn’t necessarily has to be filecoin.
…………..
In a space where there is a lot of noise, it is always refreshing to find projects with real concrete use cases, so I’ll definitely keep an eye on this duo.
If you agree and would like to learn more about IPFS and Filecoin beyond this introductory overview, make sure to let me know so I can prepare a part 2 with more information!
Thanks for making it this far! If you enjoyed it, hit like, subscribe, and share, so more people can find us!